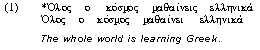

Learning Greek with an Adaptive and Intelligent Hypermedia System
Trude
Heift, Simon Fraser University
Janine Toole, Simon Fraser University
Paul McFetridge, Simon Fraser
University
Fred Popowich, Simon Fraser
University
Stavroula Tsiplakou, Simon
Fraser University
Abstract
This
paper reports on a course-support system for English learners of Greek which
is built around an Intelligent Language Tutoring System (ILTS). Meaningful interaction
between the learner and the system is achieved by a number of means: First,
students provide natural language input rather than selecting exclusively from
among pre-defined answers. Second, the ILTS uses Natural Language Processing
to analyze the learner's input and to provide error-specific feedback. Third,
the system contains a Student Model which keeps a record of students' performance
histories. The information about each learner in the Student Model determines
the level of specificity of feedback messages, clues, and exercise difficulty.
In addition to vocabulary and grammar exercises, the system also contains oral
dialogues with translations, a glossary, and cultural information. The system
is designed for introductory learners of Greek and is implemented on the World
Wide Web.
1. Introduction
As the Web begins to mature and technologies for adapting existing content in language learning converge with increased bandwidth, the desire grows to develop uniquely Web-based applications. Convenient access, currency and variety of material, and integrated multi-media can extend traditional language instruction, but truly new forms require a more profound degree of interactivity than provided by conventional forms.
Interactivity has become a key term in Hyper/Multimedia and although it is used extensively, its definition and scope is still not precisely determined. However, Laurel [1991] provides a useful definition by making a distinction between frequency, range, significance, and participatoriness. With respect to frequency and range, we may count the number of times a user can interact with a system and how many choices are available, respectively. Significance and participatoriness both require a qualitative analysis to determine how the users choices affected matters and to which degree the user is participating in ongoing system decisions [Ashworth 1996]. But to achieve a high degree of interactivity with respect to significance and participatoriness, the software requires intelligence to consider users' individual differences. For example, students learn at a different pace and have different sets of skills. These student variables need to be considered for a system to be highly interactive.
The course-support material described in this paper differs from others in that it is built around an interactive Intelligent Language Tutoring System (ILTS). Interactivity is achieved in a number of ways. The system provides a wide range of exercises covering vocabulary and grammar practice. For some tasks, students provide natural language input rather than selecting exclusively from among pre-defined answers. The tasks are independent of each other and the exercise types range from drill-and-practice to more game-like tasks. In addition, the system contains oral dialogues, a glossary, and cultural information. Significance and participatoriness are achieved through Natural Language Processing (NLP) and Student Modeling. The system consists of a grammar and a parser which analyzes student input and provides error-specific feedback. The system also maintains a Student Model which keeps a record of students ongoing performance, alters system decisions accordingly, and provides learner model updates.
In the following, we will first discuss the goals of the system and address the grammar, parser, and Student Model components. We will then describe the modules involved in analyzing student input. Further we will illustrate the exercise types of the system and provide examples of learner modeling for each of them. Finally, we will provide results of a system trial and conclude with suggestions for further implementations.
2. Goal and System Requirements
The goal of the ILTS for Greek is to provide meaningful and interactive vocabulary/grammar practice for English learners of Greek. Meaningful tasks and interactivity require intelligence on the part of the computer program. Unlike existing course-support systems which use simpler grammar practice and feedback mechanisms, the ILTS for Greek emulates two significant aspects of student-teacher interaction: it provides error-specific feedback and allows for individualization of the learning process [see Heift, 1998, 1999]. In example [1] the student provided an incorrect Greek sentence:
In such an instance, the system will detect an error in subject-verb agreement and, in addition, will tailor its feedback to suit the learners expertise. Tailoring feedback messages according to student level follows the pedagogical principle of guided discovery learning. According to Elsom-Cook [1988], guided discovery takes the student along a continuum from heavily structured, tutor-directed learning to a point where the tutor plays less of a role. Messages are scaled on a continuum from least-to-most specific, guiding the student towards the correct answer.
There are three learner levels considered in the system: novice, intermediate, and advanced. For example the novice will receive the most detailed feedback: You have made a subject-verb agreement error . The intermediate learner will be informed that an error in agreement occurred. In contrast, the advanced learner will merely be told that an error exists. The central idea is that the better the language skills of the learner, the less feedback is needed to guide the student towards the correct answer. This analysis, however, requires
a) an NLP component that can analyze ill-formed sentences, and
b) a Student Model that keeps a record of the learner.
The NLP component consists of a grammar, lexicon and parser. The grammar and lexicon use typed feature structures in an ALE style extension of Prolog [see Carpenter and Penn, 1994]. The grammar and lexicon are processed by LOPE, which is a phrase structure parsing and definite clause programming system. A distinguishing feature of LOPE is the manner in which it supports the parsing of phrases containing conflicting values in their feature structures. Definite Clause Grammars (DCGs), like other unification-based grammars, place an important restriction on parsing, that is, if two or more features do not agree in their values, a parse will fail. However, in a language learning system, these are the kinds of mistakes made by learners. To parse ungrammatical sentences, the Greek grammar contains rules which are capable of parsing ill-formed input (buggy rules) and which apply if the grammatical rules fail (see also [Schneider & McCoy, 1998], [Liou, 1991], [Weischedel, 1983], [Carbonell & Hayes, 1981]). The system keeps a record of which grammatical violations have occurred and which rules have been used but not violated. The latter is an indication of the successful application of a grammatical concept. This information is fed to the Student Model.
The Student Model is a representation of the current skill level of the student. For each student the Student Model keeps score across a number of error types, including grammar and vocabulary. For instance, the grammar nodes contain detailed information on the students performance on subject-verb agreement, case assignment, clitic pronouns, etc. The score for each node increases and decreases depending on the grammars analysis of the students performance. The amount by which the score of each node is adjusted is specified in a master file and may be weighted to reflect different pedagogical purposes.
The Student Model has two main functions:
First, the current state of the Student Model determines the specificity of the feedback message displayed to the student. A feedback message is selected according to the current score at a particular node. A student might be advanced with regard to vocabulary but a beginner with passive voice constructions. Hence, a feedback message about vocabulary would be less detailed than a feedback message about passive-voice constructions.
Second, the difficulty of the exercises presented to the student is modulated depending on the current state of the Student Model. For example, if a student is rated as advanced with respect to vocabulary, then some of the vocabulary exercises are made more challenging. The same thing can be found with some of the grammar exercises.
In the following, we will
discuss the error-checking mechanism performed by the system in analyzing student
input.
3. Error-Checking Mechanism
In addition to the grammar and the parser, the system contains additional error-checking
modules which get evoked when processing a student answer. For example, consider
the task in (2a) where the student was asked to make a sentence with the words
provided.
![]()
The student answer given
in (2b) contains a number of mistakes: an error in subject-verb agreement, a
spelling mistake, and a missing article. While the grammar will detect the agreement
error, the remaining mistakes will be discovered by additional modules of the
system. Figure 1 illustrates the modules of the Natural Language Processing
system.
Student input
![]()
Spell Check
![]()
Answer Check
![]()
Extra Word Check
![]()
Word Order Check
![]()
Grammar Check
![]()
Match Check
![]()
Feedback Message to the Learner
Figure 1. Error-checking Modules.
The first module in analyzing student input is a spell check. During the spell check, the system also extracts the base forms of each word from the grammar. The uninflected words are needed to determine whether the learner followed the task, that is, whether the student answer contained the words which were provided. Such errors cannot be determined by the grammar and the parser because these can only judge whether or not a sentence is grammatical. When defining an exercise, we store possible answers of a given task and the Answer Check module determines the most likely answer (MLA) the student intended. The Answer Check module further matches the extracted base forms with the MLA. If any of the words in the task are not contained in the student answer, the system will report an error.
The following two checks, Extra Word Check and Word Order Check, refer to additional words in the student answer and errors in word order, respectively. While these two checks are commonly handled by the grammar [Schwind, 1995], preliminary testing of our system showed that the system performs faster if these two error types are treated outside the grammar. Naturally, the speed is also influenced by the grammar formalism used.
The Grammar Check is the most elaborate of the modules. Here the sentence is analyzed by the parser according to the rules and lexical entries provided in the Greek grammar. Currently, the grammar covers a wide range of grammatical concepts, from early beginner constructions (verb 'to be' and the concept of null subjects) to fairly advanced structures (passive voice). Development is still ongoing to achieve a complete coverage of Greek grammar.
The Match Check looks for correct punctuation and capitalization by string-matching the student answer with the MLA. By this time in the evaluation process, it is very unlikely that the sentence still contains any errors other than punctuation or capitalization. If the sentence passes the Match Check successfully, the sentence is correct. If not, an error is reported to the student.
The system is organized in a way that if a module detects an error, further processing is blocked. As a result, only one error at a time will be displayed to the learner. This was implemented mainly to avoid overloading the student with extensive error reports in the case of multiple errors. According to van der Linden [1993], displaying more than one feedback message at a time makes the correction process too complex for the student. After correcting the error, the student restarts the checking mechanism by clicking the CHECK button.
In the last section, we
will briefly describe the six exercise types implemented in the system and discuss
the role of the Student Model for each.
4. Exercise Types
The system consists of three vocabulary and three grammar exercise types: Guess the Word, Find the Word, Which Word is Different, Word Order Practice, Fill-in-the-Blank, and Build a Sentence, respectively. Student performance in each exercise contributes to the Student Model. However, the nodes that get updated for each exercise differ. In addition, there are two ways in which this information is used by the system:
1) feedback messages tailored
to student expertise
2) difficulty of exercise presented to student
In the following, we will discuss the nodes which get updated and illustrate the feedback message and exercise difficulty modulation for each exercise type.
Vocabulary
Guess the Word
This is a slight variation of the vocabulary game Hangman where students guess
a word by entering one letter at a time. To avoid making this a purely guessing
game, a clue is provided for each word. This clue may be the English equivalent
of the answer as given in Figure 2, or a picture or sound representing the answer.
If the student provides an incorrect letter a piece of the picture disappears.
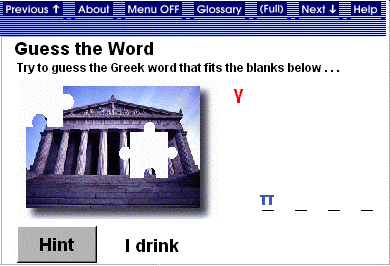
Figure 2. Guess the
Word.
Find the Word
In this exercise, students
need to find several words in a grid. The system increments the vocabulary node
for each word found and decrements it for each incorrect guess. The maximum
increments and decrements per game are equal to the number of words in the table.
The feedback messages are the same for all students. The exercise difficulty
is modulated: advanced students receive clues in English, while other students
receive clues in Greek. An example of this exercise type is given in Figure
3.
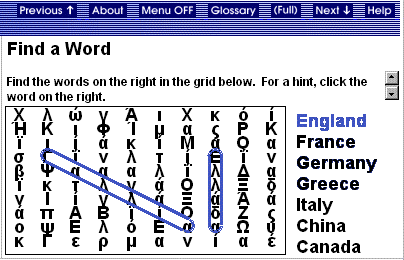
Figure 3. Find a Word.
Which Word Is Different
This exercise displays a
number of words all except one of which belong to the same category. The student
task is to identify the one that differs from the others. The divergent word
may differ syntactically, semantically or pragmatically from the remaining words.
There is an increment for each correct word selected, for each incorrect selection
a decrement is recorded. The feedback messages are the same for all students
and there is no difficulty modulation. An example of this exercise type is given
in Figure 4.
Figure 4. Which Word
Is Different.
![]() An interactive demo (23 KB) of the "Which Word Is Different".
An interactive demo (23 KB) of the "Which Word Is Different".
Shockwave plugin required.
Grammar
Word Order Practice
In this exercise, students
practice Greek word order with a drag and drop task: words have to be arranged
in an appropriate order to form a grammatical Greek sentence. An example is
given in Figure 5. For this exercise type, the word order node in the Student
Model is updated. For a sentence with incorrect word order, the system records
a decrement, else an increment. There is no feedback or difficulty modulation
for this exercise.
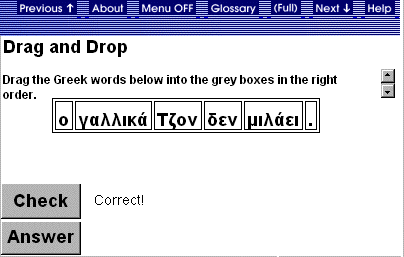
Figure 5. Word Order
Practice.
Fill-in-the-Blank
The student's task here is
to complete sentences by filling in any blanks that appear in the example. The
Student Model records each grammar node that is detected in the student input.
For example, if students are asked to supply the correct conjugation of the
verb, then the system records an increment/decrement for subject-verb agreement.
The feedback messages are modulated according to the level of the learner. Also,
advanced learners obtain more difficult tasks. For instance, novice and intermediate
students will find only one blank per example. Advanced students may be presented
with examples that contain more than one blank.
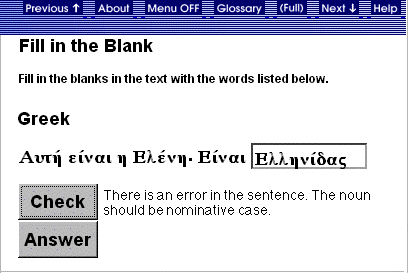
Figure 6. Fill in
the Blank.
Build a Sentence
In this exercise type, students
are provided with a set of words. Their task is to create a grammatical Greek
sentence using all the provided words. An example is given in Figure 6. All
grammar nodes activated during the processing of the students input are updated
in the Student Model. An increment is recorded if this aspect of the students
answer was correct. A decrement is recorded for any grammatical errors made
by the student. Feedback messages reflect the current state of the learners
expertise, as represented by the Student Model. For instance, Figure 7 displays
the feedback for an advanced learner. Feedback is minimal such that merely a
hint is provided.
![]() A screenshot movie (623 KB) shows a spelling mistake.
A screenshot movie (623 KB) shows a spelling mistake.
![]() A screenshot movie (894 KB) shows an error in word order.
A screenshot movie (894 KB) shows an error in word order.
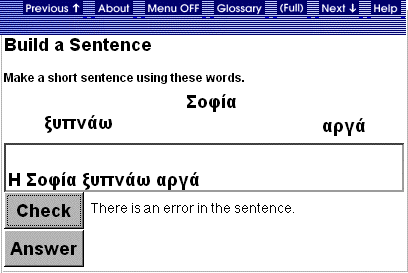
Figure 7. Build a
Sentence Feedback for the Advanced Learner.
![]() A screenshot movie (759 KB) shows an agreement error (feedback aimed at the
expert student).
A screenshot movie (759 KB) shows an agreement error (feedback aimed at the
expert student).
In contrast, the feedback for the beginner learner is very specific. An example is provided in Figure 8. There is no difficulty modulation in the build a sentence exercise type.

Figure 8. Build a
Sentence Feedback for the Beginner Learner.
![]() A screenshot movie (725 KB) shows an agreement error (feedback aimed at the
beginner student).
A screenshot movie (725 KB) shows an agreement error (feedback aimed at the
beginner student).
The modeling process has to be decided for each exercise type. Not only does the process depend on the concepts that the task makes salient, but also on the degrees of difficulty of the exercise.
![]() A screenshot movie (7.1 MB) shows the whole iterative correction process with
the three types of errors.
A screenshot movie (7.1 MB) shows the whole iterative correction process with
the three types of errors.
5. System Trial
The system was tested in an introductory-level Greek language course at Simon
Fraser University. Four hours of class time during the semester were dedicated
to using the system in class, and the seven students in the class were allowed
to access the system on their own time. At the time of the trial, content for
only two chapters was available. At the end of the trial, students completed
questionnaires that evaluated various aspects of the system.
From the questionnaires, we found that students enjoyed using the system and appreciated both that the system gave specific feedback and that the feedback was instantaneous. The students did not notice the feedback modulation, which indicated to us that the system parameters for feedback modulation need to be set so that modulation occurs more quickly. We anticipated that system speed might be an issue since the system is currently located on a rather slow web server. However, students noted that speed was not an issue it appears that they were willing to wait for the quality of feedback that the system gave. Finally, students indicated a preference for the more challenging exercises rather than ones that required less thinking. Hence, they preferred Build a Sentence, Word Order Practice, and Which Word is Different.
An analysis of student errors indicated that spelling and agreement errors were most common and capitalization, extra word, and word order errors were least common. Since the class size was quite small, it is not possible to do any statistical analysis of the data. However, even with the small sample some observations can be made. For example, Greek differs from English (the native language of most of the students) because Greek requires determiners (such as the and a) in places where English does not. Hence, one would expect to find errors such as missing determiners and extra determiners due to native language transfer. However, these extra-word errors and missing-word errors were both less frequent than spelling and agreement errors. This indicates that learning should focus on spelling and agreement since students seem to be mastering the use of the determiners.
6. Conclusions
In this paper, we discussed an interactive course-support system on the WWW. Interactivity is achieved by a wide variety of exercise types which are arranged in an independent order. NLP and Student Modeling also contribute to the interactivity of the whole system by providing error-specific feedback and adjusting to different learners. The Student Model is based on the performance history of the student. The information about each learner is recorded in the Student Model and determines the level of specificity of feedback messages and exercise difficulty.
We plan to enhance the system by adding more content, implementing the remaining grammatical constructions and expanding the exercise types. We are also further testing system performance and the pedagogical impact of the interactive Hypermedia system.
7. References
Ashworth, D. [1996]. Hypermedia and CALL. In Pennington, M. C. (ed.). The Power of CALL. Athelstan Publications, Houston, USA.
Carbonell, J. G. and Hayes, P. J. (1981). Dynamic strategy selection in flexible parsing. Proceedings of ACL 19th Annual Meeting. 143-147.
Carpenter, B., and Penn, Gerald. (1994). The Attribute Logic Engine: Users Guide, Version 2.0. Computational Linguistics Program, Carnegie Mellon University, Pittsburgh.
Elsom-Cook, M. (1993). Student Modelling in Intelligent Tutoring Systems. The Artificial Intelligence Review, 7 (3-4): 227- 240.
Heift, T. [1998]. Designed Intelligence: A Language Teacher Model. Ph. D. Dissertation, Simon Fraser University, Canada.
Heift, T. and McFetridge, P. (1999). Exploiting the Student Model to Emphasize Language Teaching Pedagogy in Natural Language Processing. Computer-Mediated Language Assessment and Evaluation in Natural Language Processing, ACL/IALL: 55-62.
Liou, H.-C. (1991). Development of an English Grammar Checker: A Progress Report. CALICO Journal, 9: 27-56.
Pennington, M. C. [1996]. The Power of CALL. Athelstan Publications, Houston, USA.
Schwind, C. B. (1995). Error Analysis and Explanation in Knowledge Based Language Tutoring. Computer Assisted Language Learning, 8 (4): 295-325.
Schneider, D. and McCoy, K. [1998]. Recognizing Syntactic Errors in the Writing of Second Language Learners. Proceedings of the 17th International Conference on Computational Linguistics.
Van der Linden, E. (1993). Does Feedback Enhance Computer-Assisted Language Learning. Computers & Education, 21 (1-2): 61-65.
Weischedel, R.M. and Sondheimer, N.J. (1983). Meta-Rules as a Basis for Processing Ill-Formed Input. American Journal of Computational Linguistics, Special Issue on Ill-Formed Input, 9 (3-4): 161-177.
8. Acknowledgements
We would like to thank the
Greek Ministry of Education for generously supporting this project. The authors
are greatly indebted to Dan Fass, Devlan Nicholson, Gordon Tisher and Davide
Turcato for the work they did on the implementation, testing and evaluation
of the system described in this article.
| IMEJ multimedia team member assigned to this paper | Yue-Ling Wong |