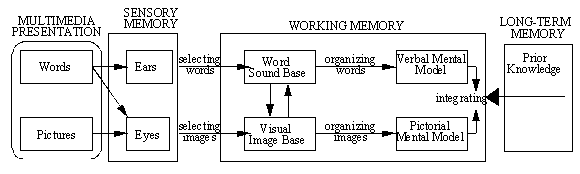
Figure 1. Depiction of a cognitive theory of multimedia learning.

A Learner-Centered Approach to Multimedia Explanations: Deriving Instructional
Design Principles from Cognitive Theory
Roxana
Moreno,
University of New Mexico
Richard E. Mayer, University
of California Santa Barbara
Abstract
How can we help
students understand scientific systems? One promising approach involves multimedia
presentations of explanations in visual and verbal formats, such as presenting
a computer-generated animation synchronized with narration or on-screen text.
In this paper, we present a cognitive theory of multimedia learning from which
the following six principles of instructional design are derived and tested:
the split-attention principle, the spatial contiguity principle, the temporal
contiguity principle, the modality principle, the redundancy principle, and
the coherence principle.
1. Designing a Multimedia
Explanation
Humans can integrate information from different sensory modalities into one
meaningful experience--such as when they associate the sound of thunder with
the visual image of lightning in the sky. They can also integrate information
from verbal and non-verbal information into a mental model--such as when they
watch lightning in the sky and listen to an explanation of the event. Therefore,
the instructional designer is faced with the need to choose between several
combinations of modes and modalities to promote meaningful learning (Moreno
& Mayer, 2000). Should the explanation be given auditorily in the form of speech,
visually in the form of text, or both? Would entertaining adjuncts in the form
of words, environmental sounds, or music help students' learning? Should the
visual and auditory materials be presented simultaneously or sequentially? To
help answer these questions, we conducted a series of studies where the learning
outcomes of students who viewed alternative presentation formats were compared.
In particular, we compared the problem-solving transfer performance of students
who learned with and without a certain condition. All students reported low
knowledge in meteorology. Taking a learner-centered approach, we aim to understand
how multimedia explanations can be used in ways that are consistent with how
people learn. By beginning with a cognitive theory of multimedia learning, we
have been able to conduct focused research that has yielded some preliminary
principles of instructional design for multimedia explanations.
2. A Cognitive Theory
of Multimedia Learning
Our cognitive theory of multimedia learning draws on dual coding theory, cognitive
load theory, and constructivist learning theory. It is based on the following
assumptions: (a) working memory includes independent auditory and visual working
memories (Baddeley, 1986); (b) each working memory store has a limited capacity,
consistent with Sweller's (1988, 1994; Chandler & Sweller, 1992) cognitive load
theory; (c) humans have separate systems for representing verbal and non-verbal
information, consistent with Paivio's (1986) dual-code theory; (d) meaningful
learning occurs when a learner selects relevant information in each store, organizes
the information in each store into a coherent representation, and makes connections
between corresponding representations in each store (Mayer, 1997). Figure 1
depicts a cognitive theory of multimedia learning with these assumptions.
Figure 1. Depiction
of a cognitive theory of multimedia learning.
3. The Split-Attention
Principle
How should verbal information be presented to students to enhance learning from
animations: auditorily as speech or visually as on-screen text? In order to
answer this question, Mayer and Moreno (1998) asked students to view an animation
depicting the process of lightning either along with concurrent narration (Group
AN) or along with concurrent on-screen text (Group AT). A selected frame from
each presentation is presented as a shockwave movie (AN.dcr and AT.dcr).
As can be seen in Figure 2, according to the cognitive theory of multimedia learning, in the AN treatment, students represent the animation in visual working memory and represent the corresponding narration in auditory working memory. Because they can hold corresponding pictorial and verbal representations in working memory at the same time, students in group AN are better able to build referential connections between them.
![]() A
selected frame from an AN presentation is presented as a shockwave movie.
A
selected frame from an AN presentation is presented as a shockwave movie.
Shockwave plugin required.
![]() A
selected frame from an AT presentation is presented as a shockwave movie.
A
selected frame from an AT presentation is presented as a shockwave movie.
Shockwave plugin required.
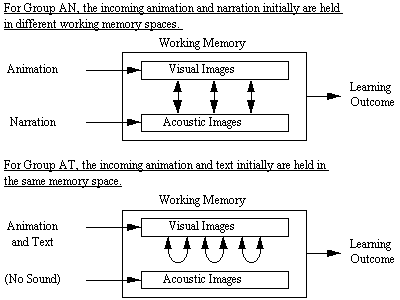
Figure 2. AN and AT
treatment.
In the AT treatment, students
try to represent both the animation and the on-screen text in visual working
memory. Although some of the visually-represented text eventually may be translated
into an acoustic modality for auditory working memory, visual working memory
is likely to become overloaded. If students pay full attention to on-line text
they may miss some of the crucial images in the animation, but if they pay full
attention to the animation they may miss some of the on-line text. Because they
may not be able to hold corresponding pictorial and verbal representations in
working memory at the same time, students in group AT are less able to build
connections between these representations. Therefore, our theory predicts that
students in group AT perform less successfully than students in group AN on
the transfer tests.
3.1 Method and Results
Seventy-eight college students viewed the animation with either concurrent narration
in a male voice describing 8 major steps in lightning formation (Group AN) or
concurrent on-screen text involving the same words and presentation timing (Group
AT).
Group AN generated significantly (p< .001) more correct solutions than Group AT on the transfer test. These results are consistent with the predictions of the cognitive theory of multimedia learning and allow us to infer the first instructional design principle, called the split-attention principle by the cognitive load theory (Chandler & Sweller, 1992; Mousavi, Low, & Sweller, 1995).
3.2 Split-Attention
Principle
Students learn better when the instructional material does not require them
to split their attention between multiple sources of mutually referring information.
4.1 Method and Results
A hundred and thirty-seven college students viewed the animation in one of the
following six conditions: one group of students viewed concurrently on-screen
text while viewing the animation (TT), a second group of students listened concurrently
to a narration while viewing the animation (NN), a third group of students listened
to a narration preceding the corresponding portion of the animation (NA), a
fourth group listened to the narration following the animation (AN), a fifth
group read the on-screen text preceding the animation (TA), and the sixth group
read the on-screen text following the animation (AT).
The text groups (TT, AT, and TA) scored significantly lower than the narration groups (NN, AN, and NA) in problem solving transfer (p < .001). These results reflect a modality effect. Within each modality group, there was no significant difference in their performance for transfer. The results from this study are consistent with prior studies on text and diagrams (Mousavi, Low, & Sweller, 1995), and allow us to infer a second instructional design principle--the Modality Principle.
4.2 Modality Principle
Students learn better when the verbal information is presented auditorily as
speech rather than visually as on-screen text both for concurrent and sequential
presentations.
5. The Redundancy Principle
Many multimedia learning scenarios include the presentation of visual materials
(such as animations, video, or graphics) with simultaneous text and audio. Would
the presentation of redundant verbal information enhance learning when students
need to simultaneously process an animation? To answer this question, we compared
the learning outcomes of four groups of students. Two groups were presented
with an animation and concurrent explanation about the formation of lightning
via narration (Group AN) or via narration and on-screen text (Group ANT) and
two groups received an animation preceding the explanation via narration (Group
A-N) or via narration and on-screen text (Group A-NT).
5.1 Method and Results
Sixty-nine college students participated in this study. A two-way analysis of
variance with the between subjects factors being redundant or non-redundant
verbal information (A-NT and ANT versus A-N and AN, respectively) and simultaneous
or sequential presentation order (AN and ANT versus A-N and A-NT, respectively)
failed to reveal that students generated significantly more conceptual creative
solutions when the verbal material was redundant than when it was not. However,
students who received sequential presentations generated more conceptual creative
solutions on the transfer test than those who received simultaneous presentations
( p < .0005).
Most importantly, a significant interaction between redundancy and presentation order for the transfer score was found (p = .05). Consistent with the predictions of a dual-processing theory of multimedia learning, students presented with redundant verbal materials outperformed students who learned with non-redundant verbal materials when the presentations are sequential. For simultaneous presentations of animations and explanations, the opposite was true: a split-attention effect between the on-screen text and the animation occurs and the redundant message hurts rather than helps students' learning. This finding allows us to infer a third principle of instructional design.
5.2 Redundancy Principle
Students learn better from animation and narration than from animation, narration,
and text if the visual information is presented simultaneously to the verbal
information.
6. The Spatial Contiguity
Principle
How does the physical integration of on-screen text and visual materials affect
students' learning? Mayer and Moreno's study on split-attention (1998) showed
that students who learn with concurrent narration and animations outperform
those who learn with concurrent on-screen text and animations. One interpretation
for this result is that students might be missing part of the visual information
while they are reading the on-screen text (or vice versa). In a review of ten
studies concerning whether multimedia instruction is effective, Mayer (1997)
concluded that there was consistent evidence for what was called a spatial-contiguity
effect. Students generated a median of over 50% more creative solutions to transfer
problems when verbal and visual explanations were integrated than when they
were separated (Mayer, 1997). In order to extend these studies to multimedia
learning with animations, we conducted a study where the physical proximity
of the on-screen text and the animation was manipulated (Moreno & Mayer, 1999,
Experiment 1). As can be seen from the selected frames in Figure 3, one group
of students had on-screen text that was integrated or physically close to the
animation (IT group) while a second group of students had on-screen text that
was separated or physically far from the animation (ST group). A third group
of students saw a presentation with concurrent animation and narration (N group).
This study allows us to interpret performance differences between the text groups
(IT and ST) in terms of spatial-contiguity and performance difference between
the narration (N) and text groups (IT and ST) in terms of modality.
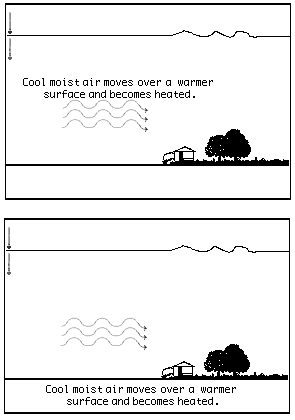
Figure 3. Selected
frames showing one group of students had on-screen text that was integrated
or physically close to the animation (IT group) while a second group of students
had on-screen text that was separated or physically far from the animation (ST
group).
6.1 Method and Results
One hundred and thirty-two college students participated in this study. The
results indicated that the N group scored significantly higher than the IT and
ST groups in the transfer test, with the IT group scoring significantly higher
than the ST group (p < .001). The findings are evidence for both a modality
and a spatial-contiguity effect in transfer. Hence, it is possible to infer
a fourth instructional design principle.
6.2 Spatial Contiguity
Principle
Students learn better when on-screen text and visual materials are physically
integrated rather than separated.
7. The Temporal Contiguity
Principle
How synchronized in time do the verbal and visual materials have to be for students
to learn better from animations? Congruent with a dual-processing model of working
memory, meaningful learning is fostered when the learner is able to hold a visual
representation in visual working memory and a corresponding verbal representation
in verbal working memory at the same time. The model implicates working memory
load as a major impediment to learning. Although all learners may receive identical
animation and narration in a multimedia environment, the amount of information
that they are forced to hold in working memory at one time might affect performance.
For example, presenting the whole animation preceded or followed by the whole
narration successively (which we will call large bites), can overload working
memory such that it is not possible to hold all of the narrative in working
memory until the animation is presented (or vice versa). However, if we present
one chunk of animation--depicting only a short sequence--preceded or followed
by one corresponding chunk of narration and so on (which we will call small
bites), and if the size of the chunk does not exceed working memory capacity,
then the learner should be able to make connections between the corresponding
words and pictures--in the same way as when animation and narration are presented
concurrently.
Our prior study (Moreno
& Mayer, 1999) failed to find performance differences between the simultaneous
and sequential narration groups. Similar results were obtained for learning
with geometry examples by simultaneous and sequential explanations (Mousavi,
Low & Sweller, 1995). In both cases, the successive presentations of the animation
and narration were small bites, only a line or two at a time, and thus unlikely
to overload working memory. However, in another set of studies (Mayer & Anderson,
1991, 1992), where large bites of animation and narrations were presented successively,
students in the simultaneous conditions outperformed students who learned with
sequential presentations. In order to reconcile the above findings, we varied
the size of the units that were presented sequentially to the learners (Mayer,
Moreno, Boire & Vagge, 1999). One group of students saw a presentation with
concurrent animation and narration (concurrent group), a second group of students
either viewed the whole animation followed or preceded by the whole explanatory
narration (large bites group) and a third group of students either viewed small
chunks of animation followed or preceded by small chunks of explanatory narration
(small bites group).
7.1 Method and Results
The participants were 60 college students. The large bites group scored significantly
lower than the concurrent and small bites groups in the transfer test (p < .0001).
The concurrent and small bites groups did not differ from each other. These
results allow all prior studies in temporal contiguity to be reconciled if the
length of the cycles in the sequential presentations is taken into account.
Therefore, a fifth instructional design principle for multimedia learning with
animations can be inferred.
7.2 Temporal Contiguity
Principle
Students learn better when verbal and visual materials are temporally synchronized
rather than separated in time.
8. The Coherence Principle
Would entertaining adjuncts in the form of sounds, or music help students' learning
from a multimedia explanation? According to the cognitive theory of multimedia
learning, learners process multimedia messages in their visual and auditory
channels--both of which are limited in capacity. In the case of a narrated animation,
the animation is processed in the visual channel and the narration is processed
in the auditory channel. When additional auditory information is presented,
it competes with the narration for limited processing capacity in the auditory
channel. When processing capacity is used to process the music and sounds, there
is less capacity available for processing the narration, organizing it into
a coherent cause-and-effect chain, and linking it with the incoming visual information.
Based on this theory, we can predict that adding interesting music and sounds
to a multimedia presentation will hurt students' learning. In order to test
this prediction, Moreno and Mayer (2000) asked students to view an animation
depicting the process of lightning either with concurrent narration (Group N),
with concurrent narration and environmental sounds (Group NE), with concurrent
narration and music (Group NM), or with concurrent narration, environmental
sounds and music (Group NEM).
8.1 Method and Results
Seventy-five college students participated in this study. Students scored significantly
lower in the transfer test when music had been presented than when no music
had been presented (p < .0001); but there was no significant difference between
students who received environmental sounds and those who didn't. There was a
significant interaction between music and sounds (p < .05), in which the combination
of music and environmental sounds (Group NEM) was particularly detrimental to
transfer performance. Supplemental tests indicated that students in Group NEM
had transfer scores significantly lower than each of the other groups and that
Group NM had transfer scores significantly lower than Groups N and NE, which
did not differ from each other. There was no significant interaction between
music and environmental sounds.
This pattern supports the hypothesis derived from the cognitive model of multimedia learning. Adding extraneous auditory material--in the form of music--tended to hurt students' understanding of the lightning process. Adding relevant and coordinated auditory material--in the form of environmental sounds--did not hurt students' understanding of the lightning process. The findings suggest that auditory overload can be created by adding auditory material that does not contribute to making the lesson intelligible. The results of this auditory overload are that fewer of the relevant words and sounds may enter the learner's cognitive system and fewer cognitive resources can be allocated to building connections among words, images, and sounds. Therefore, a sixth instructional design principle for multimedia learning with animations can be inferred.
8.2 Coherence Principle
Students learn better when extraneous material is excluded rather than included
in multimedia explanations.
9. Conclusion
Multimedia explanations allow students to work easily with verbal and non-verbal
representations of complex systems. The present review demonstrates that presenting
a verbal explanation of how a system works with an animation does not insure
that students will understand the explanation unless research-based principles
are applied to the design.
The present studies have important theoretical implications. According to a generative theory of multimedia learning (Mayer, 1997), active learning occurs when a learner engages three cognitive processes--selecting relevant words for verbal processing and selecting relevant images for visual processing, organizing words into a coherent verbal model and organizing images into a coherent visual model, integrating corresponding components of the verbal and visual models. To foster the process of selecting, multimedia presentations should not contain too much extraneous information in the form of words or sounds. To foster the process of organizing, multimedia presentations should represent the verbal and non-verbal steps in synchrony. To foster the process of integrating, multimedia presentations should present words and pictures using modalities that effectively use available visual and auditory working memory resources. The major advance in our research program is to identify techniques for presentation of verbal and visual information that minimizes working memory load and promotes meaningful learning.
10. References
Baddeley, A. D. (1986). Working memory. Oxford, England: Oxford University
Press.
Chandler, P. & Sweller, J. (1992). The split-attention effect as a factor in the design of instruction. British Journal of Educational Psychology, 62, 233-246.
Mayer, R. E. (1997). Multimedia learning: Are we asking the right questions? Educational Psychologist, 32, 1-19.
Mayer, R. E. & Anderson, R. B. (1991). Animations need narrations: An experimental test of a dual-coding hypothesis. Journal of Educational Psychology, 83, 484-490.
Mayer, R. E. & Anderson, R. B. (1992). The instructive animation: Helping students build connections between words and pictures in multimedia learning. Journal of Educational Psychology, 84, 444-452.
Mayer, R. E. & Moreno, R. (1998). A split-attention effect in multimedia learning: Evidence for dual processing systems in working memory. Journal of Educational Psychology, 90, 312-320.
Mayer, R. E., Moreno, R., Boire M., & Vagge S. (1999). Maximizing constructivist learning from multimedia communications by minimizing cognitive load. Journal of Educational Psychology , 91, 638-643.
Moreno, R. & Mayer, R. E. (2000). A coherence effect in multimedia learning: The case for minimizing irrelevant sounds in the design of multimedia instructional messages. Journal of Educational Psychology, 97, 117-125.
Moreno, R. & Mayer, R. E. (1999). Cognitive principles of multimedia learning: The role of modality and contiguity. Journal of Educational Psychology, 91, 358-368.
Mousavi, S.Y., Low, R., & Sweller, J. (1995). Reducing cognitive load by mixing auditory and visual presentation modes. Journal of Educational Psychology, 87, 319-334.
Paivio, A. (1986). Mental representation: A dual coding approach. Oxford, England: Oxford University Press.
Sweller, J. (1988). Cognitive load during problem solving: Effects on learning. Cognitive Science, 12, 257-285.
Sweller, J., Chandler, P. (1994). Why some material is difficult to learn. Cognition and Instruction, 12, 185-233.
| IMEJ multimedia team member assigned to this paper | Yue-Ling Wong |