2. Goal and System
Requirements
The goal of the ILTS
for Greek is to provide meaningful and interactive vocabulary/grammar
practice for English learners of Greek. Meaningful tasks and interactivity
require intelligence on the part of the computer program. Unlike existing
course-support systems which use simpler grammar practice and feedback
mechanisms, the ILTS for Greek emulates two significant aspects of student-teacher
interaction: it provides error-specific feedback and allows for individualization
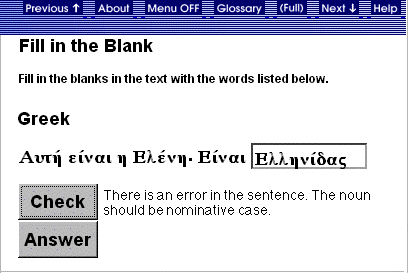
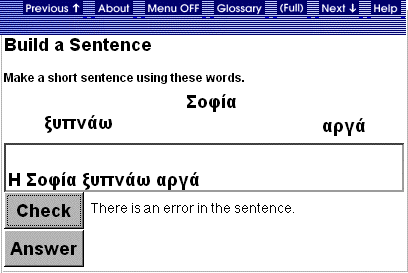
of the learning process [see Heift, 1998, 1999]. In example [1] the student
provided an incorrect Greek sentence:
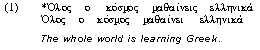
In such an instance,
the system will detect an error in subject-verb agreement and, in addition,
will tailor its feedback to suit the learners expertise. Tailoring feedback
messages according to student level follows the pedagogical principle
of guided discovery learning. According to Elsom-Cook [1988], guided discovery
takes the student along a continuum from heavily structured, tutor-directed
learning to a point where the tutor plays less of a role. Messages
are scaled on a continuum from least-to-most specific, guiding the student
towards the correct answer.
There are three learner
levels considered in the system: novice, intermediate, and advanced. For
example the novice will receive the most detailed feedback: You have
made a subject-verb agreement error . The
intermediate learner will be informed that an error in agreement occurred.
In contrast, the advanced learner will merely be told that an error exists.
The central idea is that the better the language skills of the learner,
the less feedback is needed to guide the student towards the correct answer.
This analysis, however, requires
a)
an NLP component that can analyze ill-formed sentences, and
b)
a Student Model that keeps a record of the learner.
The NLP component
consists of a grammar, lexicon and parser. The grammar and lexicon use
typed feature structures in an ALE style extension of Prolog [see Carpenter
and Penn, 1994]. The grammar and lexicon are processed by LOPE, which
is a phrase structure parsing and definite clause programming system.
A distinguishing feature of LOPE is the manner in which it supports the
parsing of phrases containing conflicting values in their feature structures.
Definite Clause Grammars (DCGs), like other unification-based grammars,
place an important restriction on parsing, that is, if two or more features
do not agree in their values, a parse will fail. However, in a language
learning system, these are the kinds of mistakes made by learners. To
parse ungrammatical sentences, the Greek grammar contains rules which
are capable of parsing ill-formed input (buggy rules) and which apply
if the grammatical rules fail (see also [Schneider & McCoy, 1998],
[Liou, 1991], [Weischedel, 1983], [Carbonell & Hayes, 1981]). The
system keeps a record of which grammatical violations have occurred and
which rules have been used but not violated. The latter is an indication
of the successful application of a grammatical concept. This information
is fed to the Student Model.
The Student Model
is a representation of the current skill level of the student. For each
student the Student Model keeps score across a number of error types,
including grammar and vocabulary. For instance, the grammar nodes
contain detailed information on the students performance on subject-verb
agreement, case assignment, clitic pronouns, etc. The score for each node
increases and decreases depending on the grammars analysis of the students
performance. The amount by which the score of each node is adjusted is
specified in a master file and may be weighted to reflect different pedagogical
purposes.
The Student Model
has two main functions:
First, the current
state of the Student Model determines the specificity of the feedback
message displayed to the student. A feedback message is selected according
to the current score at a particular node. A student might be advanced
with regard to vocabulary but a beginner with passive voice constructions.
Hence, a feedback message about vocabulary would be less detailed than
a feedback message about passive-voice constructions.
Second, the difficulty
of the exercises presented to the student is modulated depending on the
current state of the Student Model. For example, if a student is rated
as advanced with respect to vocabulary, then some of the vocabulary exercises
are made more challenging. The same thing can be found with some of the
grammar exercises.
In the following,
we will discuss the error-checking mechanism performed by the system in
analyzing student input.