![]()
A Learner-Centered Approach to Multimedia Explanations: Deriving Instructional
Design Principles from Cognitive Theory
Roxana
Moreno,
University of New Mexico
Richard E. Mayer, University
of California Santa Barbara
Abstract
How can
we help students understand scientific systems? One promising approach
involves multimedia presentations of explanations in visual and verbal
formats, such as presenting a computer-generated animation synchronized
with narration or on-screen text. In this paper, we present a cognitive
theory of multimedia learning from which the following six principles
of instructional design are derived and tested: the split-attention principle,
the spatial contiguity principle, the temporal contiguity principle, the
modality principle, the redundancy principle, and the coherence principle.
1. Designing a
Multimedia Explanation
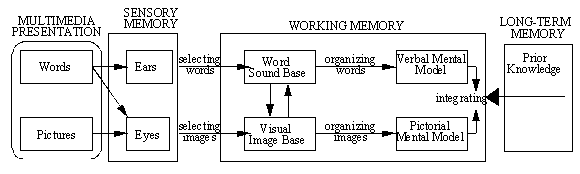
Humans can integrate information from different sensory modalities into
one meaningful experience--such as when they associate the sound of thunder
with the visual image of lightning in the sky. They can also integrate
information from verbal and non-verbal information into a mental model--such
as when they watch lightning in the sky and listen to an explanation of
the event. Therefore, the instructional designer is faced with the need
to choose between several combinations of modes and modalities to promote
meaningful learning (Moreno & Mayer, 2000). Should the explanation be
given auditorily in the form of speech, visually in the form of text,
or both? Would entertaining adjuncts in the form of words, environmental
sounds, or music help students' learning? Should the visual and auditory
materials be presented simultaneously or sequentially? To help answer
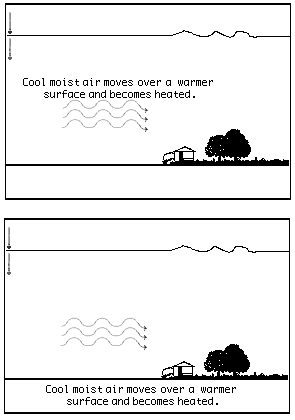
these questions, we conducted a series of studies where the learning outcomes
of students who viewed alternative presentation formats were compared.
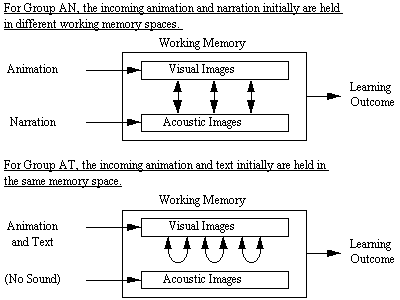
In particular, we compared the problem-solving transfer performance of
students who learned with and without a certain condition. All students
reported low knowledge in meteorology. Taking a learner-centered approach,
we aim to understand how multimedia explanations can be used in ways that
are consistent with how people learn. By beginning with a cognitive theory
of multimedia learning, we have been able to conduct focused research
that has yielded some preliminary principles of instructional design for
multimedia explanations.
![]()